The "spurious" IRQ messages are annoying when one is logged onto the system console at the tower. They are logged at a priority of "warning". They should have a lower priority, like debug, or info, unless the number/sec is above some threshold. Until that change is made, I'll disable them on the console, by setting the "-c 4" option in klogd, which then suppresses messages of warning and lower, which are numeric values 4-8. 3-0 are priorities from error to emerg.
That change was made to /etc/init.d/klogd on Oct 24, 16:45 UTC, and klogd restarted.
To see the spurious messages, do either of the following:
cat /proc/kmsg dmesg
cat /proc/kmsg removes the messages from the kernel message ring buffer as they are read.
Oct 14, 2011
Arrived: 9am MDT
Departed: 11am MDT
ChrisG and SteveS are on site to diagnose the sick licor 7500 at 16m and add the two licors that were at the CWEX11 project.
Chris could not hear the motor spinning on the 16m Licor 7500. A power cycle did not bring it back. While removing it, when the unit bumped against something, the motor started up, but was much more noisy than usual. It will be brought back for repair.
Installed SN 1167 at 16 meters, and 0813 at 7 meters. 30 meters still has no Licor.
From Boulder I (Gordon) set the sampling rate to 10 Hz and the baud rate to 9600. The Licors had been configured for 20 Hz, 19200 baud. From minicom, after adn:
adn minicom ttyS7 (or ttyS11) ctrl-a w (enable line wrap) ctrl-a e (enable local echo) ctrl-a f (send BREAK) (Outputs (BW 10) (Delay 0) (RS232 (Freq 10.0) (Baud 9600))) ctrl-a q aup
They also swapped out the three main batteries.
Also checked tensions.
The data from the Licor at 16 meters went bad on Oct 2, while our system was not reachable over the network.
http://www.eol.ucar.edu/isf/projects/BEACHON_SRM/isfs/qcdata/plots/2011/10/02/co2_20111002.png
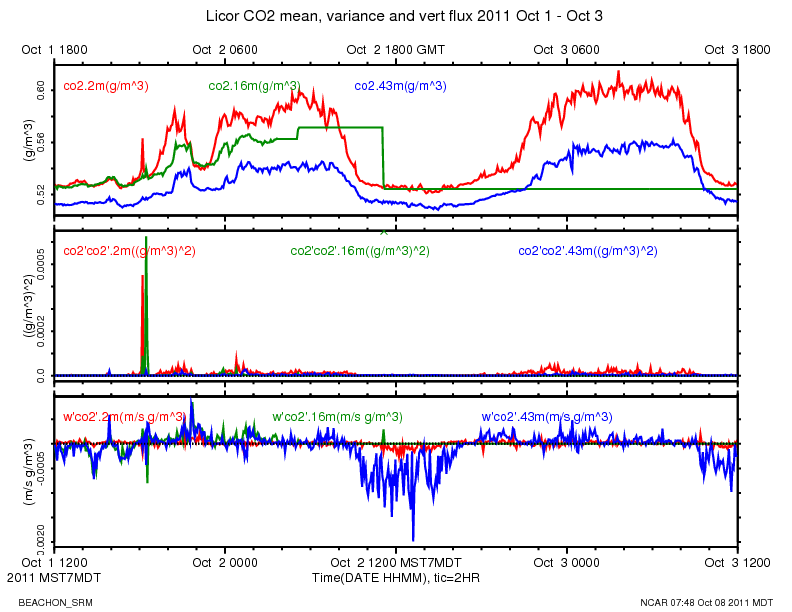{kind=link}
The ldiag averages went from the typical 248-255 range to around 216.
http://www.eol.ucar.edu/isf/projects/BEACHON_SRM/isfs/qcdata/plots/2011/10/02/licor_20111002.png
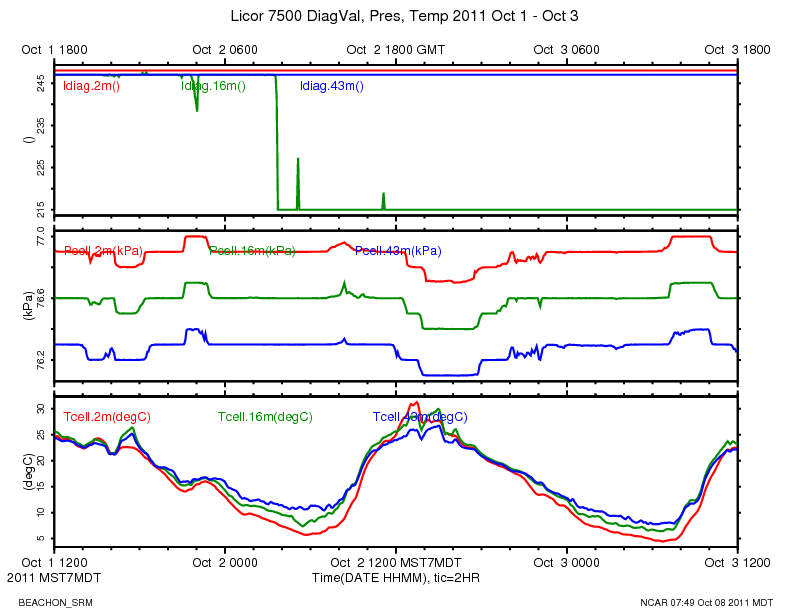{kind=link}
This CWEX11 logbook entry has some information about the licor diagnostic value:
This morning at around 10:40 MDT, I logged in and looked at the high rate data with rserial. (The 16 meter licor is serial port 11) The diagnostic value is 215 = 11010111 binary. Bit 5 is 0 indicating the PLL is not OK.
According to the manual:
PLL - Phase Lock Loop offset, indicates the status of the chopper motor. If not OK, there may be a problem with the chopper motor in the sensor head.
Also just noticed there is not data on the plots from the 2 meter licor since 04:00 MDT this morning. That appears to be a moisture issue. I just logged in and did rserial (serial port 2):
rs 2 255\t0.11124\tOverflow\t0.11690\tOverflow\t2.77\t76.0\t\n 255\t-45877.11718\tOverflow\t-37005.95312^D\tOverflow\t2.78\t76.0\t\n 255\t-59961.00781\tOverflow\t-110557.73437\tOverflow\t2.77\t76.0\t\n 255\t0.86791\tOverflow\t0.94173\tOverflow\t2.79\t76.0\t\n
The \t are tabs between the values. 255 is the ldiag value, indicating a high AGC value, but all other diagnostic bits are OK. The second and fourth values in a message are the raw values for co2 and h2o, which look crazy, and the calibrated values are "Overflow". This will probably clear up when things dry out.
We have not been able to reach the turbulence tower data system since Sep 29.
We could ping the RAL server in the seatainer from Boulder. Andy Gaydos logged into the server and could not ping the data system: 192.168.100.202. So either the data system or the network between the seatainer and the tower was down.
On Oct 6 I was able to ssh to the DSM. So somebody fixed the problem, or perhaps a fiber<->copper transceiver reset itself.
I did not see anything in /var/log/isfs/messages about eth0 going down/up.
The DSM did not go down, so it wasn't a DSM power problem:
root@manitou root# date Thu Oct 6 22:44:24 GMT 2011 root@manitou root# uptime 22:45:18 up 464 days, 3:22, 2 users, load average: 0.02, 0.05, 0.00